Datadog Summit London 2026: Key Takeaways
The views I express here are mine alone and do not necessarily reflect the opinions or official position of my employer.
The Datadog Summit in London brought together observability leaders and platform engineers to discuss the future of monitoring and cloud infrastructure management. As a software & data engineer, attending this summit reinforced the importance of understanding observability across the entire system, not just isolated components. Datadog's focus on comprehensive monitoring, alerting, and hands-on workshops provided valuable insights into how teams can leverage observability platforms to build more reliable and efficient systems.
Keynote Highlights
This year's keynotes featured industry leaders discussing significant advancements in real-time monitoring, AI-driven anomaly detection, and unified log aggregation across distributed systems. The speakers addressed key pain points that organizations currently face, including:
Observability and Security for the AI Era

DataDog Summit London 2026 - Yrieix Garnier Presentation
Yrieix Garnier, VP of Product at Datadog, highlighted the five key pillars of observability and how Datadog’s platform addresses the needs of a broad audience—not just data teams, but the entire technology stack. The talk covered observability for AI agents, large language models (LLMs), machine learning platforms (such as Amazon SageMaker and Azure Machine Learning), data pipelines (including Snowflake, dbt, Airflow, Databricks, and BigQuery), and GPU monitoring. Datadog introduced an all-in-one solution featuring Bits AI agents for SREs, developers, and security analysts to accelerate the remediation process through "Detect, Act, Decide" cycle. Learn more in the Bits AI documentation.
Building a Brand-Safe AI Concierge at Virgin Atlantic
Mark O'Neill, Senior Manager of Applied AI Engineering at Virgin Atlantic, shared valuable insights into deploying AI solutions while upholding brand integrity and organizational values. He emphasized the challenges of AI hallucinations—where models generate inaccurate or out-of-context responses—and the critical need for robust LLM guardrails especially in public-facing applications. These guardrails act as technical controls and safety mechanisms, ensuring AI behavior remains safe, reliable, and compliant.
Mark illustrated this with a memorable example involving Chipotle chatbot that, when LLM chatbot left unchecked, would answer any question—even solving linked list problems for customers. While this might delight users (especially when it is running on free credits for customer), it can lead to unintended business consequences. His talk underscored the importance of balancing innovation with responsible AI governance, especially as organizations increasingly rely on AI-powered customer interactions.
To Virgin Atlantic, it was the most important to have No PII data, no logged-in state and read-only operations simple system design diagram of how they've managed to resolve it
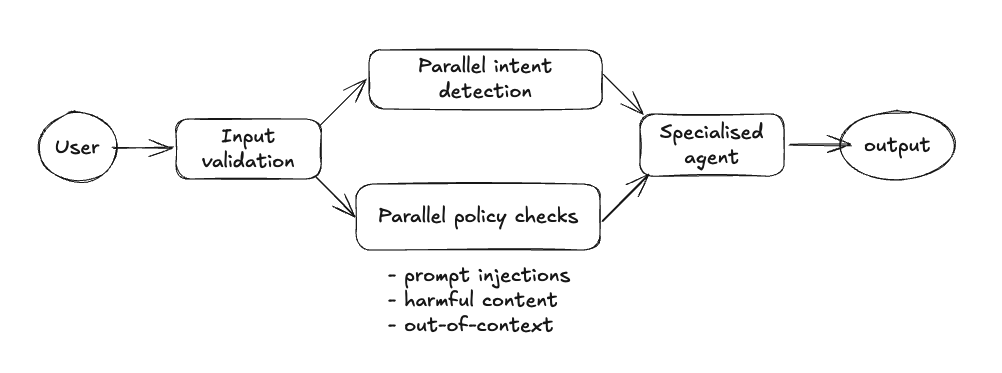
Adapted from Building a Brand-Safe AI Concierge at Virgin Atlantic Presentation
Virgin Atlantic adopted a structured red-teaming framework to ensure their AI systems remain safe and aligned with brand values.
Their approach included:
- Creating a harmful query dataset: They compiled prompts across various risk categories to rigorously test the system’s boundaries.
- Generating persuasive jailbreak prompts: Using techniques like priming, positive emotional appeal, and compensation framing, they crafted over 1,000 adversarial prompts through using "How Johnny Can Persuade LLMs to Jailbreak Them". For more details, see the persuasive jailbreaker.
- Evaluating against guardrails: Each prompt was tested to ensure the AI’s responses stayed within established safety and compliance guidelines.
Mark emphasized that LLM behavior should be treated like production software: it must be testable, observable, and enforceable. Most importantly, evaluation should be independent, so don’t mark your own homework.
Engineering Real-Time Sports Trading at Global Scale
Adam Hope, Global Trading CTO, delivered an insightful talk on engineering real-time data pipelines and ultra-low-latency calculations for sports betting. In this industry, true real-time processing is critical, not just for user experience, but to prevent arbitrage opportunities that can arise from even minor delays. Adam described how their systems are designed to process updates within 400 ms, leveraging technologies like Kafka and optimizing latency from 50 ms down to under 1 ms.
This raises an important question: how real-time do dashboards and analytics need to be for most organizations? While ultra-low-latency is essential for trading and betting platforms, many business dashboards can tolerate higher latencies, especially if the data is primarily used for decision-making rather than automated actions. For most companies, running intensive analytics or dashboard updates during off-peak hours (such as end-of-day) can help balance performance and resource usage.
Reflecting on this, it's clear that the value of real-time dashboards depends on the use case. For mission-critical, high-frequency environments, every millisecond counts. For others, near-real-time or batch updates may be sufficient, allowing teams to focus optimization efforts where they matter most.
Log Querying and Analytics: Beginner to Advanced workshop
I participated in the "Log Querying and Analytics: Beginner to Advanced" hands-on workshop, one of three offered at the summit. Although I already use Datadog in my daily work, the workshop revealed just how much untapped potential the platform has for deeper log analysis and troubleshooting. The practical exercises demonstrated advanced querying techniques, log pattern detection, and real-time analytics that can significantly improve incident response and root-cause analysis. Inspired by the session, I plan to pursue Datadog certification to further expand my expertise and help my team leverage the platform more effectively.
Additional Insights from Datadog Summit London 2026
A key framework emphasized at the summit was the end-to-end incident response lifecycle:
observation → root cause analysis (RCA) → action → outcome
This approach highlights the importance of not just detecting issues, but systematically investigating their origins, taking informed actions, and measuring the results. By adopting this structured process, teams like us can continuously improve system reliability and accelerate incident resolution.
Looking Ahead
Overall, the insights and presentations at Datadog Summit London 2026 were highly impactful and well-delivered. The ongoing convergence of observability, AI, and automation is reshaping how engineering teams detect, respond to, and prevent incidents. Organizations that embrace these advancements will be better positioned to enhance system reliability, streamline operations, and maintain a competitive edge in an increasingly complex technology landscape.
For more information, please visit Datadog Summit London 2026.